一、JVM 异常处理逻辑
public class TestClass {
private static int len = 779;
public int add(int x){
try {
// 若运行时检测到 x = 0,那么 jvm会自动抛出异常,(可以理解成由jvm自己负责 athrow 指令调用)
x = 100/x;
} catch (Exception e) {
x = 100;
}
return x;
}
}
# 编译
javac TestClass.java
# 使用javap 查看 add 方法被编译后的机器指令
javap -verbose TestClass.class
public int add(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=2
0: bipush 100 // 加载参数100
2: iload_1 // 将一个int型变量推至栈顶
3: idiv // 相除
4: istore_1 // 除的结果值压入本地变量
5: goto 11 // 跳转到指令:11
8: astore_2 // 将引用类型值压入本地变量
9: bipush 100 // 将单字节常量推送栈顶<这里与数值100有关,可以尝试修改100后的编译结果:iconst、bipush、ldc>
10: istore_1 // 将int类型值压入本地变量
11: iload_1 // int 型变量推栈顶
12: ireturn // 返回
// 注意看 from 和 to 以及 targer,然后对照着去看上述指令
Exception table:
from to target type
0 5 8 Class java/lang/Exception
LineNumberTable:
line 6: 0
line 9: 5
line 7: 8
line 8: 9
line 10: 11
StackMapTable: number_of_entries = 2
frame_type = 72 /* same_locals_1_stack_item */
stack = [ class java/lang/Exception ]
frame_type = 2 /* same */

-
个人理解,from 和 to 相当于划分区间,只要在这个区间内抛出了type 所对应的,“java/lang/Exception” 异常(主动athrow 或者 由jvm运行时检测到异常自动抛出),那么就跳转到target 所代表的第八行。
-
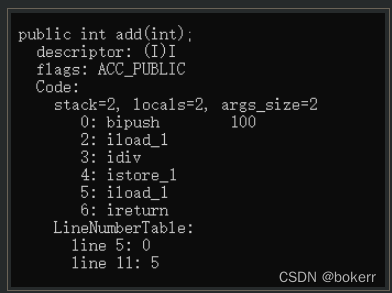
如果硬是要说的话,用了try catch 编译后指令篇幅变长了;goto 语句跳转会耗费性能,当你写个数百行代码的方法的时候,编译出来成百上千条指令,这时候这句goto的带来的影响显得微乎其微。如图所示为去掉try catch 后的指令篇幅,几乎等同上述指令的前五条。
二、关于JVM的编译优化
1. 分层编译
2. 即时编译器
-
解释模式
-
编译模式
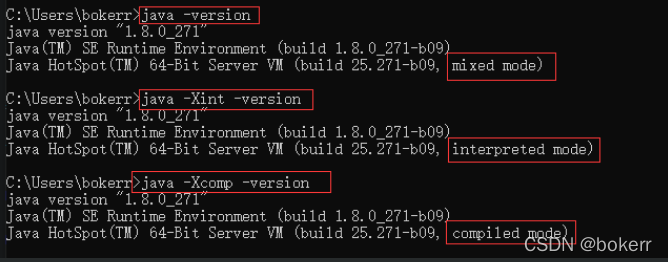
# 强制虚拟机运行于 "编译模式"
-Xcomp
# 方法调用次数计数器阈值,它是基于计数器热点代码探测依据[Client模式=1500,Server模式=10000]
-XX:CompileThreshold=10
# 关闭方法调用次数热度衰减,使用方法调用计数的绝对值,它搭配上一配置项使用
-XX:-UseCounterDecay
# 除了热点方法,还有热点回边代码[循环],热点回边代码的阈值计算参考如下:
-XX:BackEdgeThreshold = 方法计数器阈值[-XX:CompileThreshold] * OSR比率[-XX:OnStackReplacePercentage]
# OSR比率默认值:Client模式=933,Server模式=140
-XX:OnStackReplacePercentag=100
-
提前编译器:jaotc 它是后端编译的另一个主角,它有两个发展路线,基于Graal [新时代的主角] 编译器开发,因为本文用的是 C2 编译器,所以只对它做一个了解;
三、关于测试的约束
四、测试代码
public class ExecuteTryCatch {
// 100W
private static final int TIMES = 1000000;
private static final float STEP_NUM = 1f;
private static final float START_NUM = Float.MIN_VALUE;
public static void main(String[] args){
int times = 50;
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
// 每个方法执行 50 次
while (--times >= 0){
System.out.println("times=".concat(String.valueOf(times)));
executeTryCatch.executeMillionsEveryTryWithFinally();
executeTryCatch.executeMillionsEveryTry();
executeTryCatch.executeMillionsOneTry();
executeTryCatch.executeMillionsNoneTry();
executeTryCatch.executeMillionsTestReOrder();
}
}
/**
* 千万次浮点运算不使用 try catch
* */
public void executeMillionsNoneTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("noneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算最外层使用 try catch
* */
public void executeMillionsOneTry(){
float num = START_NUM;
long start = System.nanoTime();
try {
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
} catch (Exception e){
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("oneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算循环内使用 try catch
* */
public void executeMillionsEveryTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("evertTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算循环内使用 try catch,并使用 finally
* */
public void executeMillionsEveryTryWithFinally(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
} finally {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("finalTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算,循环内使用多个 try catch
* */
public void executeMillionsTestReOrder(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e){}
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("orderTry sum:" + num + " million:" + million + " nao: " + nao);
}
}
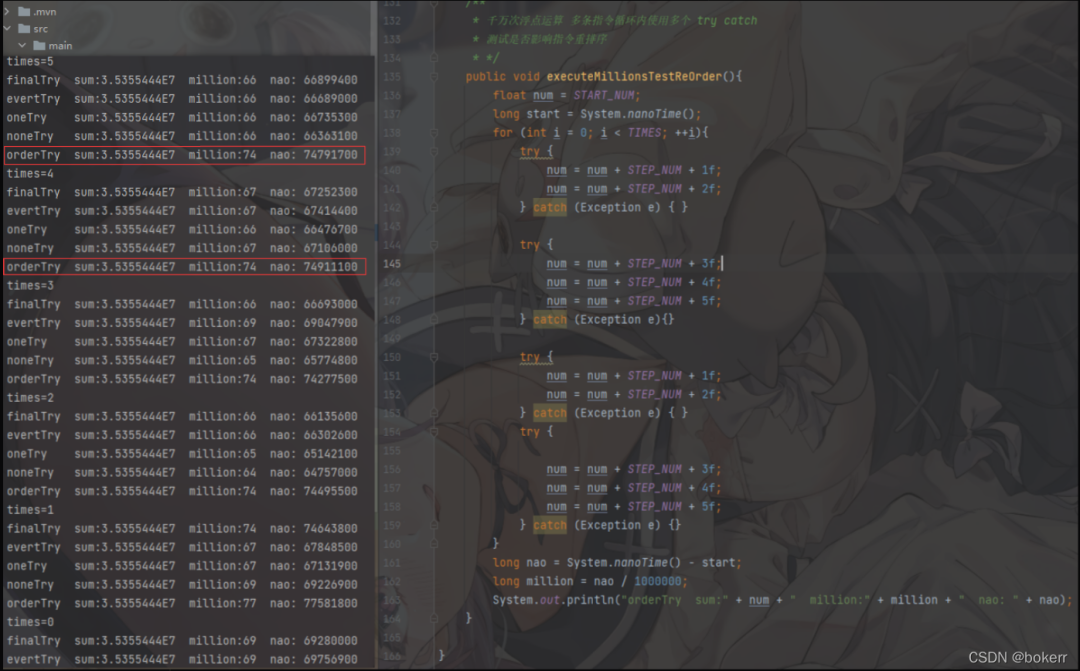
五、解释模式下执行测试
-Xint
-XX:-BackgroundCompilation
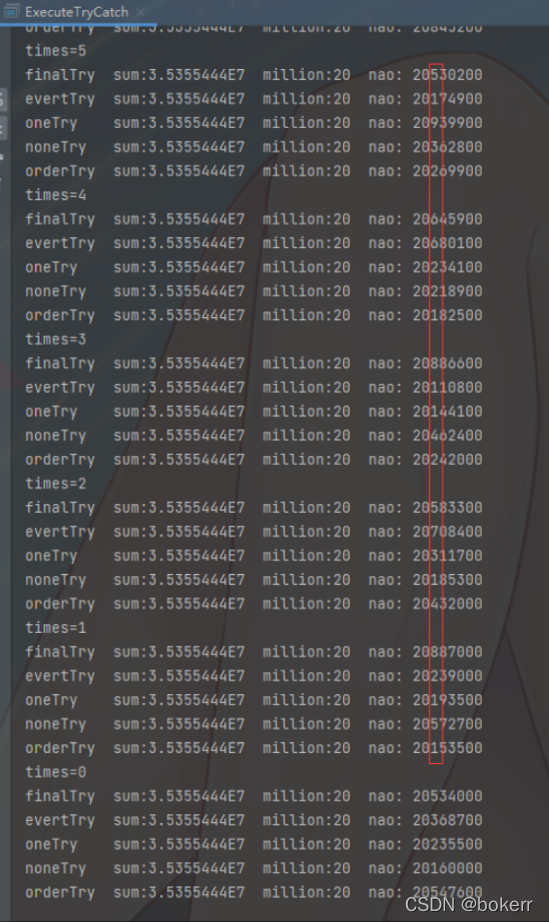
六、编译模式测试
-Xcomp
-XX:CompileThreshold=10
-XX:-UseCounterDecay
-XX:OnStackReplacePercentage=100
-XX:InterpreterProfilePercentage=33
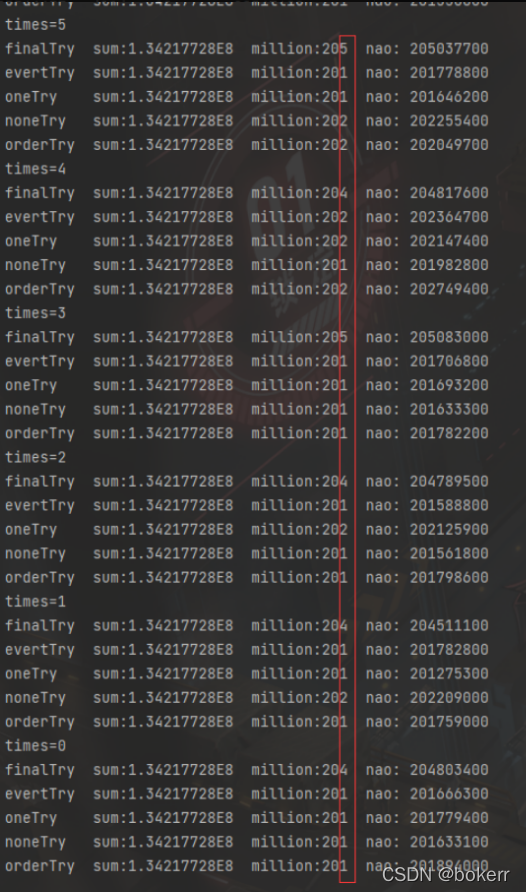
七、结论
private int getThenAddNoJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("参数异常");
int num;
try {
// 不校验 key 是否未空值,直接调用 toString 每次触发空指针异常并被捕获
num = 100 + Integer.parseInt(URLDecoder.decode(json.get(key).toString(), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
private int getThenAddWithJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("参数异常");
int num;
try {
// 校验 key 是否未空值
num = 100 + Integer.parseInt(URLDecoder.decode(Objects.toString(json.get(key), "0"), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
public static void main(String[] args){
int times = 1000000;// 百万次
long nao1 = System.nanoTime();
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddWithJudge(new JSONObject(), "anyKey");
}
long end1 = System.nanoTime();
System.out.println("未抛出异常耗时:millions=" + (end1 - nao1) / 1000000 + "毫秒 nao=" + (end1 - nao1) + "微秒");
long nao2 = System.nanoTime();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddNoJudge(new JSONObject(), "anyKey");
}
long end2 = System.nanoTime();
System.out.println("每次必抛出异常:millions=" + (end2 - nao2) / 1000000 + "毫秒 nao=" + (end2 - nao2) + "微秒");
}

往期推荐