

代码测试环境:Hadoop2.4
应用场景:当需要定制输出数据格式时可以采用此技巧,包括定制输出数据的展现形式,输出路径,输出文件名称等。
Hadoop内置的输出文件格式
- FileOutputFormat<K,V> 常用的父类;
- TextOutputFormat<K,V> 默认输出字符串输出格式;
- SequenceFileOutputFormat<K,V> 序列化文件输出;
- MultipleOutputs<K,V> 可以把输出数据输送到不同的目录;
- NullOutputFormat<K,V> 把输出输出到/dev/null中,即不输出任何数据,这个应用场景是在MR中进行了逻辑处理,同时输出文件已经在MR中进行了输出,而不需要在输出的情况;
- LazyOutputFormat<K,V> 只有在调用write方法是才会产生文件,这样的话,如果没有调用write就不会产生空文件;
步骤
类似输入数据格式,自定义输出数据格式同样可以参考下面的步骤
1) 定义一个继承自OutputFormat的类,不过一般继承FileOutputFormat即可;
2)实现其getRecordWriter方法,返回一个RecordWriter类型;
3)自定义一个继承RecordWriter的类,定义其write方法,针对每个<key,Value>写入文件数据;
代码
实例1(修改文件默认的输出文件名以及默认的key和value的分隔符):
输入数据:
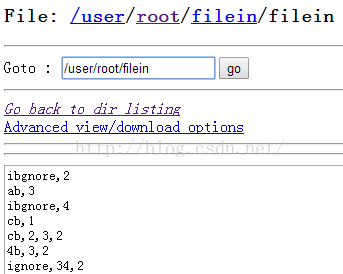
自定义CustomFileOutputFormat(把默认文件名前缀替换掉):
package fz.outputformat;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CustomOutputFormat extends FileOutputFormat<LongWritable, Text> {
private String prefix = "custom_";
@Override
public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
// 新建一个可写入的文件
Path outputDir = FileOutputFormat.getOutputPath(job);
// System.out.println("outputDir.getName():"+outputDir.getName()+",otuputDir.toString():"+outputDir.toString());
String subfix = job.getTaskAttemptID().getTaskID().toString();
Path path = new Path(outputDir.toString()+"/"+prefix+subfix.substring(subfix.length()-5, subfix.length()));
FSDataOutputStream fileOut = path.getFileSystem(job.getConfiguration()).create(path);
return new CustomRecordWriter(fileOut);
}
}
自定义CustomWriter(指定key,value分隔符):
package fz.outputformat;
import java.io.IOException;
import java.io.PrintWriter;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
public class CustomRecordWriter extends RecordWriter<LongWritable, Text> {
private PrintWriter out;
private String separator =",";
public CustomRecordWriter(FSDataOutputStream fileOut) {
out = new PrintWriter(fileOut);
}
@Override
public void write(LongWritable key, Text value) throws IOException,
InterruptedException {
out.println(key.get()+separator+value.toString());
}
@Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException {
out.close();
}
}
调用主类:
package fz.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FileOutputFormatDriver extends Configured implements Tool{
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
ToolRunner.run(new Configuration(), new FileOutputFormatDriver(),args);
}
@Override
public int run(String[] arg0) throws Exception {
if(arg0.length!=3){
System.err.println("Usage:\nfz.outputformat.FileOutputFormatDriver <in> <out> <numReducer>");
return -1;
}
Configuration conf = getConf();
Path in = new Path(arg0[0]);
Path out= new Path(arg0[1]);
boolean delete=out.getFileSystem(conf).delete(out, true);
System.out.println("deleted "+out+"?"+delete);
Job job = Job.getInstance(conf,"fileouttputformat test job");
job.setJarByClass(getClass());
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(CustomOutputFormat.class);
job.setMapperClass(Mapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(Integer.parseInt(arg0[2]));
job.setReducerClass(Reducer.class);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
return job.waitForCompletion(true)?0:-1;
}
}
查看输出:
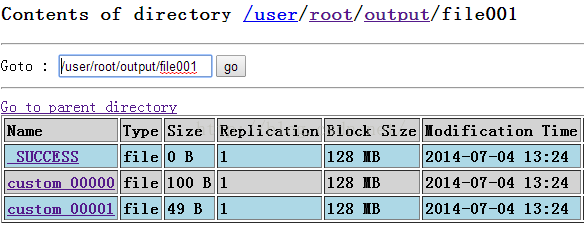
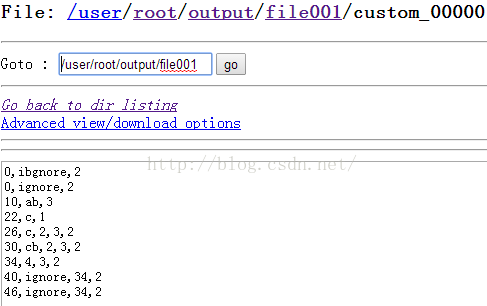
从输出结果可以看到输出格式以及文件名确实按照预想输出了。
博文转载自:http://blog.csdn.net/fansy1990







